
はじめに
こんにちは。あやかです。
Evernoteの旧PREMIUMプラン(まとめ購入)を長年使っていたんですが、いよいよ期限が来てしまいました。 現行プランだとノート数無制限で使うにはかなりの金額になるので、さすがに継続は厳しいなと。
そもそも、私のEvernoteの使い方って「PDFを添付して検索する」がほとんどだったんですよね。 だったら、Evernoteに拘らなくても、PDFの分類と全文検索ができるツールに移行すればいいのでは?と考えました。
調べた結果、Paperless-ngxというオープンソースのドキュメント管理システムに行き着いて、Synology NAS上にDockerで構築することにしました。
今回は、環境構築からEvernoteのデータ移行、iOSアプリの設定、Cloudflare Tunnel経由での外部公開まで、一通りまとめます。
なぜPaperless-ngxを選んだのか
候補として検討したツール
移行先の候補はいくつかありました。
Joplin — Evernoteの.enex形式からシームレスにインポートできるのは魅力でした。ただ、PDF添付ファイルの全文検索が標準では非対応で、プラグインで一部対応している程度。メインの用途がPDF検索なので、ちょっと厳しいなと。
Notion — メモ帳としては既に使っています。ただ、埋め込みPDFの全文検索が対象にならないケースがあったり、ワークスペースを分けると追加課金が発生したり。PDFを大量に管理する用途には向きません。
Synology Note Station — NAS付属の無料ノートアプリ。検索性やPDFプレビュー、OCR機能がEvernoteより劣ります。Windowsクライアントの動作が遅い、同期コンフリクト時のデータロスト問題もあるとのことで、不安が残りました。
Paperless-ngx — オープンソースで無料。OCR自動処理、機械学習による自動分類、PDF全文検索に特化。Docker対応でSynology NAS上に構築可能。さらに、MCP(Model Context Protocol)対応のサーバーが複数存在していて、将来的にClaude連携もできそう。
結論
Notionはメモ帳として使い続けて、PDF管理はPaperless-ngxに任せる構成にしました。 Synology NAS上にDockerで構築して、iOSアプリ(Swift Paperless)で外出先からもアクセスできる環境を目指します。
環境情報
ハードウェア
- Synology DS923+(既存のNAS)
ソフトウェア・サービス
| 名称 | 用途 | 備考 |
|---|---|---|
| Paperless-ngx v2.20.13 | ドキュメント管理本体 | Docker(ghcr.io/paperless-ngx/paperless-ngx:latest) |
| PostgreSQL 16 | データベース | Docker(docker.io/library/postgres:16) |
| Redis 7 | メッセージブローカー | Docker(docker.io/library/redis:7) |
| Gotenberg 8 | Office文書変換 | Docker(docker.io/gotenberg/gotenberg:8) |
| Apache Tika | Office文書テキスト抽出 | Docker(docker.io/apache/tika:latest) |
| Swift Paperless | iOSクライアント | App Store(無料) |
| Cloudflare Tunnel | 外部公開 | 既存環境を利用 |
| Cloudflare Access | 外部アクセスの認証保護 | Service Tokenでアプリからのアクセスをバイパス |
構築手順
1. 専用ユーザーの作成
DSMのコントロールパネル > ユーザーとグループで、Paperless-ngx用のユーザー paperless を作成しました。docker 共有フォルダへの読み書き権限を付与しています。
SSHでUID/GIDを確認します。
id paperless
# uid=1030(paperless) gid=100(users) groups=100(users)
この値は、後でdocker-compose.ymlの USERMAP_UID / USERMAP_GID に設定するのでメモしておきます。
2. フォルダ構成の作成
File Stationで /volume2/docker/paperless-ngx/ 配下に以下のフォルダを作成しました。
/volume2/docker/paperless-ngx/
├── consume/ ← 取り込み用(ここにPDFを入れると自動処理)
├── data/ ← アプリケーションデータ
├── media/ ← ドキュメント保存先
├── export/ ← バックアップエクスポート先
├── db/ ← PostgreSQLデータ
└── redis/ ← Redisデータ
3. docker-compose.ymlの作成とコンテナ起動
docker-compose.ymlを作成して、Container Managerのプロジェクト機能でコンテナを起動しました。
設定のポイントは以下の通りです。
USERMAP_UID: 1030/USERMAP_GID: 100— 手順1で確認した値PAPERLESS_OCR_LANGUAGE: jpn+eng— 日本語+英語のOCRPAPERLESS_OCR_LANGUAGES: jpn— 日本語Tesseractデータの追加ダウンロードPAPERLESS_TIME_ZONE: Asia/TokyoPAPERLESS_DATE_ORDER: YMDPAPERLESS_FILENAME_FORMAT— 年/発信元/タイトルでファイルを自動整理
4. ファイル名フォーマットの記法修正
起動時に以下の警告が出ました。
Filename format {created_year}/{correspondent}/{title} is using the old style, please update to use double curly brackets
HINT: {{ created_year }}/{{ correspondent }}/{{ title }}
Paperless-ngxの最近のバージョンで、ファイル名フォーマットの記法が旧式の {変数} からDjangoテンプレート風の {{ 変数 }} に変更されていました。docker-compose.ymlを修正してコンテナを再起動して解消しています。
最初から {{ 変数 }} の記法で書いていれば問題ないので、これから構築する方は気にしなくて大丈夫です。
ユーザー・権限の設定
管理者アカウントの作成
SSHでsuperuserを作成しました。
sudo docker exec -it paperless-ngx python3 manage.py createsuperuser
ユーザー名は admin として、管理専用にしています。
普段使い用ユーザーの作成
WebUI(adminでログイン)の Settings > ユーザー & グループ から、普段使い用ユーザー ayaka を作成しました。
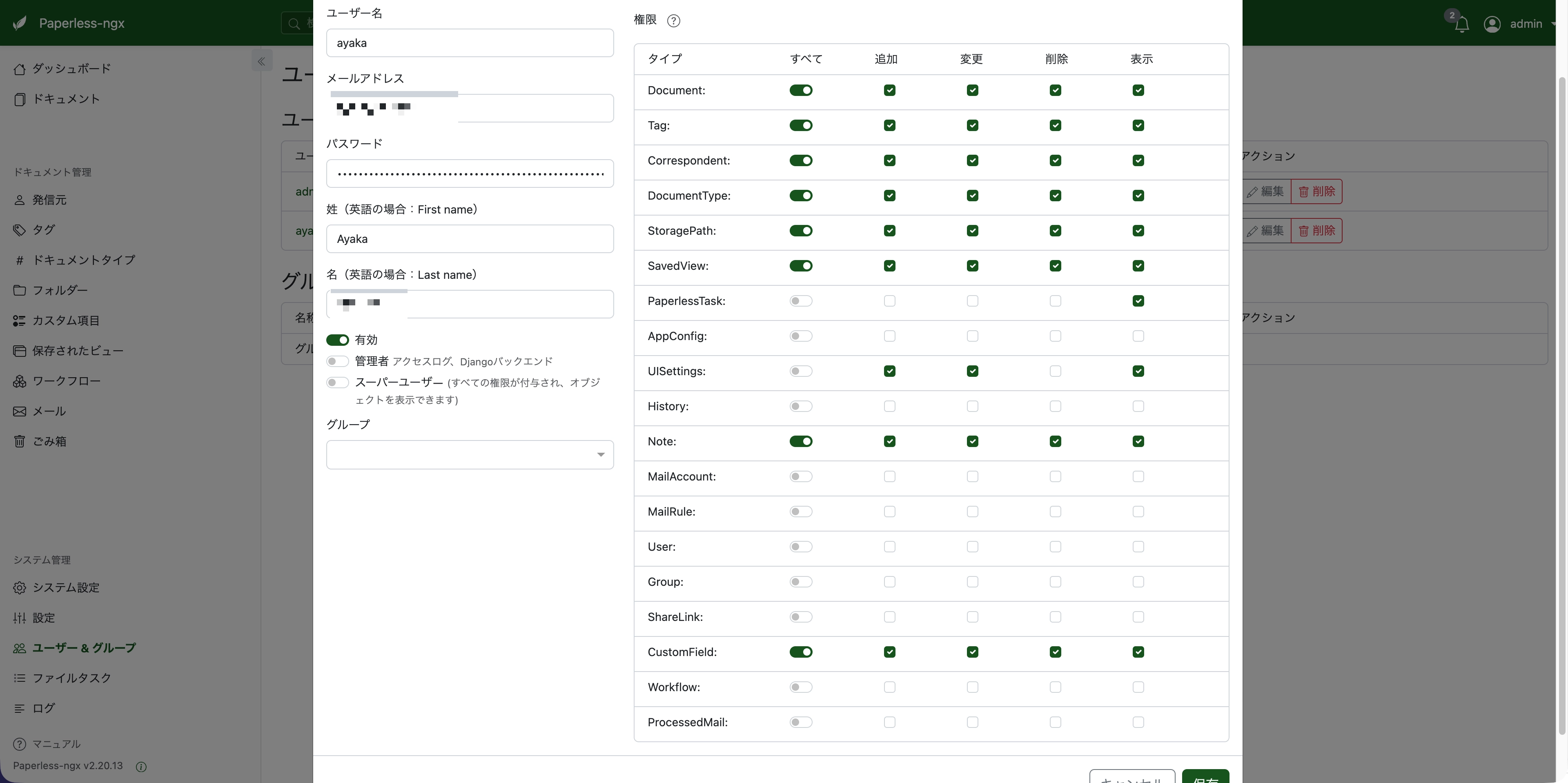
設定方針は「日常使いに困らず、万一アカウントが乗っ取られても最小限のダメージで済む権限」です。
「すべて」をONにしたもの: Document、Tag、Correspondent、DocumentType、StoragePath、SavedView、CustomField、Note
OFFにしたもの:
- User、Group — ユーザー管理はadminのみ
- MailAccount、MailRule、ProcessedMail — 外部へのデータ送信リスク防止
- PaperlessTask、AppConfig — システム設定の変更は不要
- Workflow — 権限操作されるリスク防止
- ShareLink — 外部流出防止
- History — 監査ログは不要
UISettingsは「表示」「追加」「変更」をONにしました。これがないと、ログイン直後に403エラーが出ます。地味にハマったポイントです。
「管理者」トグル、「スーパーユーザー」はどちらもOFFにしています。
OCR設定の調整
日本語OCRの確認
まず、日本語OCRが正常に動作しているか確認しました。
sudo docker exec paperless-ngx tesseract --list-langs
# jpn が含まれていることを確認
sudo docker exec paperless-ngx printenv | grep OCR
# PAPERLESS_OCR_LANGUAGE=jpn+eng
# PAPERLESS_OCR_LANGUAGES=jpn
OCRモードの変更
EvernoteからエクスポートしたPDF(特にWebページから生成されたもの)の中に、テキストレイヤーは埋め込まれているけど文字化けしているものがありました。
デフォルトの skip モードだと、テキストレイヤーがあるページはOCRがスキップされてしまいます。これでは文字化けしたテキストがそのまま残ってしまうので、redo モードに変更しました。
docker-compose.ymlのenvironmentに以下を追加します。
PAPERLESS_OCR_MODE: redo
ちなみに、redo と force の違いはこうです。
- redo — 既存のテキストレイヤーを残した上で、OCR結果を追加・上書き。元々テキストが正しく埋め込まれているページの品質は維持される。
- force — 元のテキストレイヤーを完全に破棄して、全ページを画像として扱ってOCRし直す。元々きれいだったテキストもOCR精度に依存する結果に置き換わる。
品質のバランスを考えて redo を採用しました。文字化けしたPDFだけでなく、正常なPDFも混在しているので、既存のテキストを壊さない redo の方が安全です。
ワークフローの設定
consumeフォルダのオーナー自動割り当て
consumeフォルダ経由で取り込まれたドキュメントは、デフォルトだとオーナーが設定されません。つまり、全ユーザーから見える状態になります。
セキュリティ上よろしくないので、ワークフローを作成して自動割り当てするようにしました。
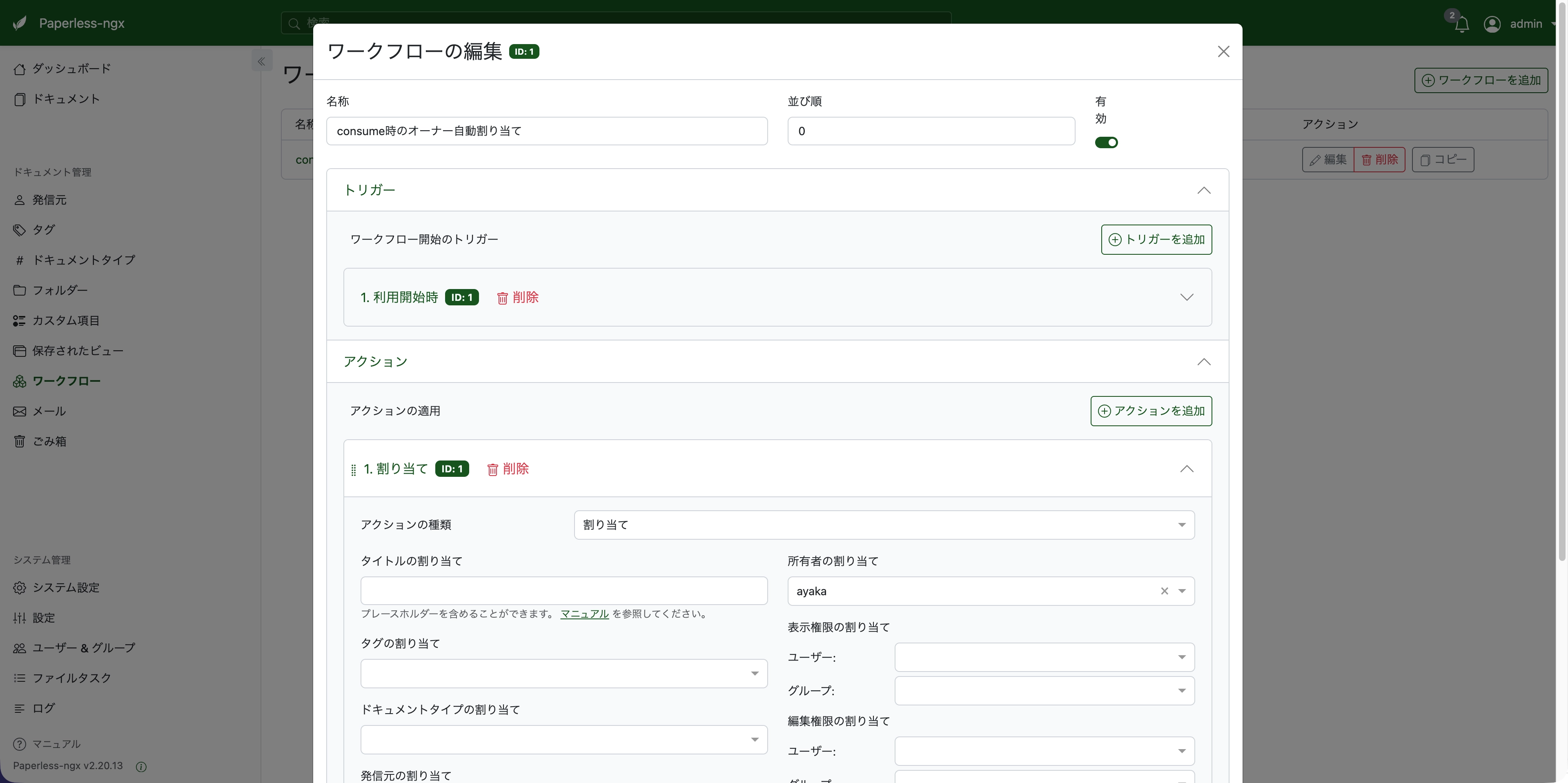
WebUIの「ワークフロー」から新規作成します。
- 名称:
consume時のオーナー自動割り当て - トリガー: 「利用開始時」(Consumption Started)、フィルターは空欄(全ファイルに適用)
- アクション: 「割り当て」でオーナーを
ayakaに設定
これで、consumeフォルダに入れたファイルは自動的に ayaka のドキュメントとして取り込まれます。
EvernoteからのPDFインポート
PDFのエクスポートとconsumeフォルダへの投入
Evernoteからエクスポート済みのPDFファイルを、consumeフォルダにコピーしました。Paperless-ngxが自動的に検出して、OCR処理とインデックス作成を実行してくれます。
大量のPDFを一度に入れると処理に時間がかかるので、100件ずつくらいに分けて投入するのがおすすめです。
重複ファイルの処理
一部のPDFがconsumeフォルダに残っていました。ログを確認したところ、既に取り込み済みのドキュメントと重複していたためでした。
Not consuming 確認 | dカード GOLDからdカードへのお切替え.pdf: It is a duplicate of 確認 | dカード GOLDからdカードへのお切替え (#588).
Evernoteからのエクスポート時に、同じファイルが重複して含まれていたことが原因です。残ったファイルは手動で削除しました。
Paperless-ngxが重複を自動検出してくれるので、うっかり同じファイルを入れてしまっても二重登録にはなりません。これは地味にありがたい機能です。
ScanSnap由来のPDF処理
ScanSnap(PFU)でスキャンしたPDFの処理時に、GhostscriptがPDFの規格非準拠を検出して警告が出ました。
This file had errors that were repaired or ignored.
The file was produced by:
>>>> PFU PDF <<<<
ただ、自動修復されて処理自体は正常に完了しました。ScanSnapユーザーは一瞬焦るかもしれませんが、この警告は致命的ではないので安心してください。
iOSアプリ(Swift Paperless)の設定
アプリのインストールとローカル接続
App Storeから「Swift Paperless」をインストールしました(無料)。
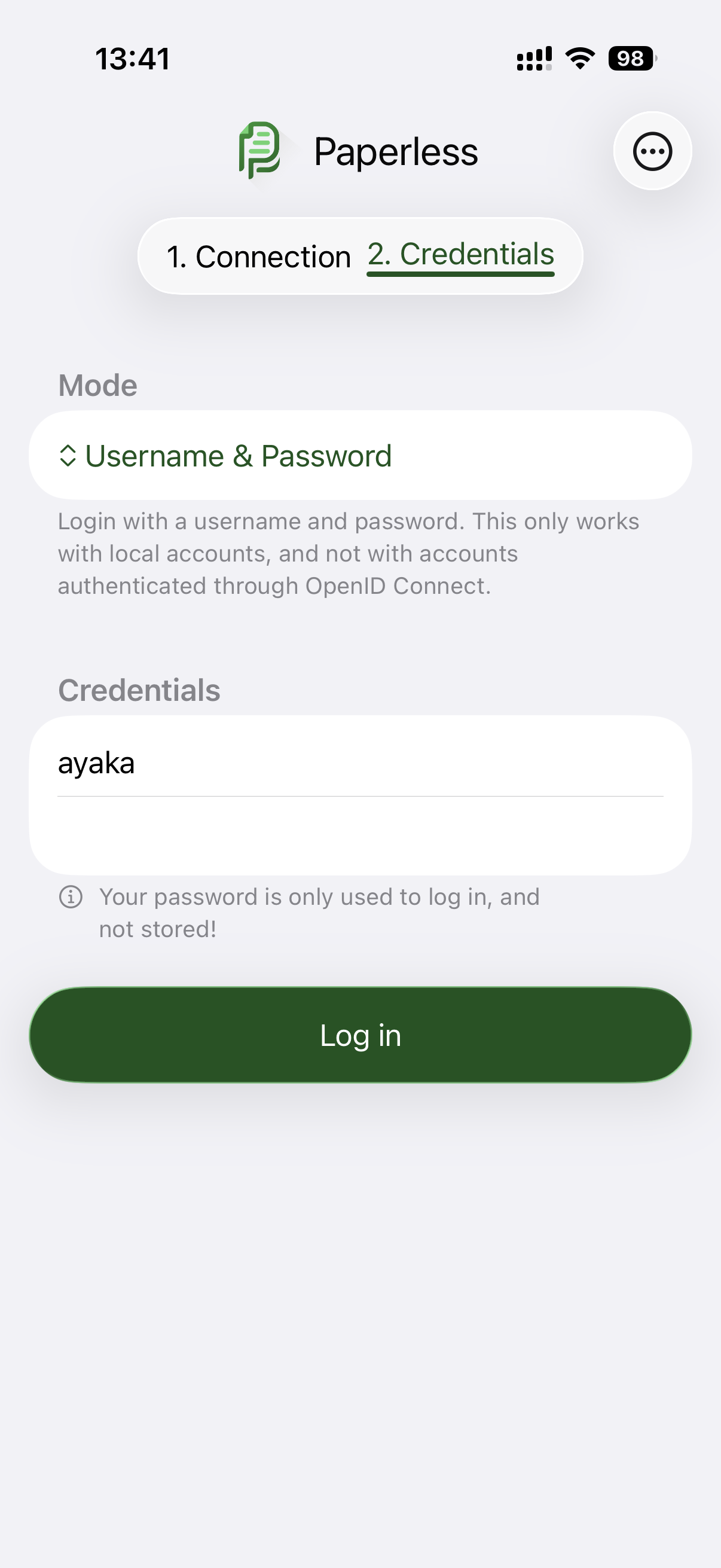
ローカル接続の設定はシンプルです。
- URL:
http://192.168.123.123:8010 - ユーザー名:
ayaka - パスワード: ayakaのパスワード
Cloudflare Access経由での外部接続
外出先からもCloudflare Tunnel経由でアクセスできるよう、Service Tokenを使ったバイパス設定を行いました。
Cloudflare側の設定
- Cloudflare Zero Trustダッシュボードで Service Token を作成(Access > Service Auth > Service Tokens)
- Client IDとClient Secretを安全な場所に保存(私は1Passwordに格納しました)
- Paperless-ngx用のAccessアプリケーションにポリシーを追加
- Action: Service Auth
- Include: 作成したService Tokenを選択
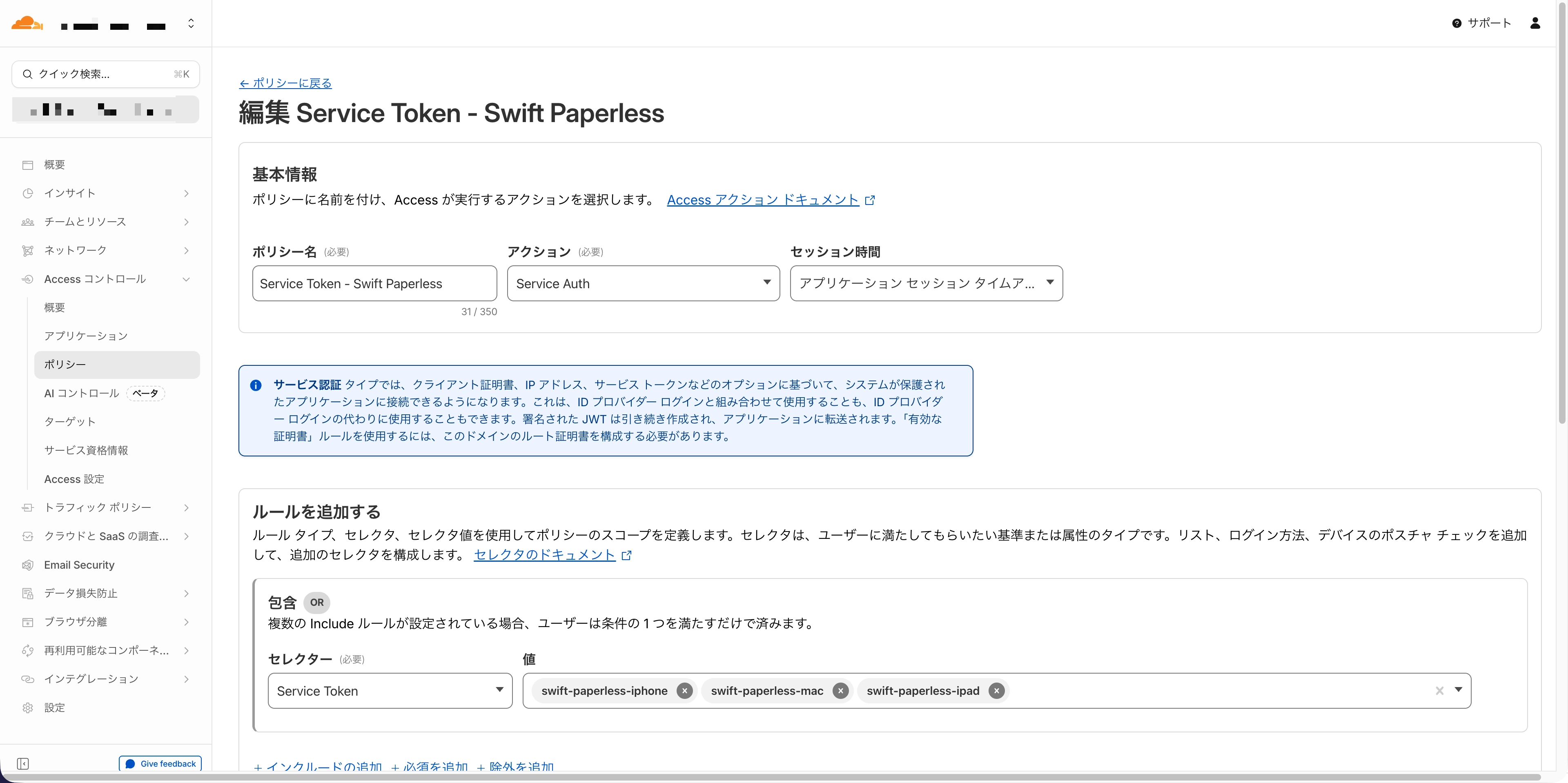
Swift Paperless側の設定
- URL:
https://paperless.example.com(Cloudflare Tunnel経由のドメイン) - ユーザー名:
ayaka - パスワード: ayakaのパスワード
- カスタムヘッダー:
CF-Access-Client-Id: Client IDの値CF-Access-Client-Secret: Client Secretの値
この構成のポイントは、アプリからのAPIリクエストがCloudflare Accessの認証画面をバイパスし、Paperless-ngx自体のユーザー認証で保護される二重構成になっていることです。
ブラウザからのアクセスにはカスタムヘッダーが付かないので、通常通りCloudflare Accessの認証画面が表示されます。つまり、アプリはService Tokenで、ブラウザはCloudflare Accessでそれぞれ保護されるわけです。
docker-compose.yml(最終版)
構築が完了した最終的なdocker-compose.ymlを掲載します。
services:
broker:
image: docker.io/library/redis:7
container_name: paperless-redis
restart: unless-stopped
volumes:
- ./redis:/data
db:
image: docker.io/library/postgres:16
container_name: paperless-db
restart: unless-stopped
volumes:
- ./db:/var/lib/postgresql/data
environment:
POSTGRES_DB: paperless
POSTGRES_USER: paperless
POSTGRES_PASSWORD: <DB用パスワード>
webserver:
image: ghcr.io/paperless-ngx/paperless-ngx:latest
container_name: paperless-ngx
restart: unless-stopped
depends_on:
- db
- broker
- gotenberg
- tika
ports:
- "8010:8000"
volumes:
- ./data:/usr/src/paperless/data
- ./media:/usr/src/paperless/media
- ./export:/usr/src/paperless/export
- ./consume:/usr/src/paperless/consume
environment:
PAPERLESS_REDIS: redis://broker:6379
PAPERLESS_DBHOST: db
PAPERLESS_DBNAME: paperless
PAPERLESS_DBUSER: paperless
PAPERLESS_DBPASS: <DB用パスワード>
PAPERLESS_TIKA_ENABLED: 1
PAPERLESS_TIKA_GOTENBERG_ENDPOINT: http://gotenberg:3000
PAPERLESS_TIKA_ENDPOINT: http://tika:9998
USERMAP_UID: 1030
USERMAP_GID: 100
PAPERLESS_TIME_ZONE: Asia/Tokyo
PAPERLESS_OCR_LANGUAGE: jpn+eng
PAPERLESS_OCR_LANGUAGES: jpn
PAPERLESS_OCR_MODE: redo
PAPERLESS_URL: https://paperless.example.com
PAPERLESS_CSRF_TRUSTED_ORIGINS: https://paperless.example.com
PAPERLESS_SECRET_KEY: <ランダムな長い文字列>
PAPERLESS_FILENAME_FORMAT: "{{ created_year }}/{{ correspondent }}/{{ title }}"
PAPERLESS_DATE_ORDER: YMD
gotenberg:
image: docker.io/gotenberg/gotenberg:8
container_name: paperless-gotenberg
restart: unless-stopped
command:
- "gotenberg"
- "--chromium-disable-javascript=true"
- "--chromium-allow-list=file:///tmp/.*"
tika:
image: docker.io/apache/tika:latest
container_name: paperless-tika
restart: unless-stopped
<DB用パスワード> と <ランダムな長い文字列> は、必ず自分で生成した値に置き換えてください。POSTGRES_PASSWORD と PAPERLESS_DBPASS は同じ値にします。
Tika/Gotenbergが不要な場合(PDFのみを扱い、Office文書の取り込みが不要なら)、gotenberg / tika サービスと関連する環境変数(PAPERLESS_TIKA_* の3行)を削除してOKです。
おわりに
Evernoteからの移行、想像していたより大変ではありませんでした。
Paperless-ngxはOCRの自動処理、重複検出、ファイル名の自動整理など、PDFの管理に必要な機能がしっかり揃っています。Evernoteで「PDFを添付して検索する」使い方をしていた人なら、十分に移行先として候補になると思います。 年間数万円のEvernoteのサブスクリプションがNASの電気代だけで済むようになったのは大きいですね。
今後は、タグや発信元の自動分類ルールの最適化や、Paperless-ngx MCPサーバーの導入(Claude連携)あたりを試してみたいと思っています。実際に試したらまた記事にする予定です。
それでは、また。